|
I'm a second-year masters student at Georgia Tech advised by Dr. Alexander Lerch in the Music Informatics Group.
I am broadly interested in topics spanning speech/audio/music and language representation learning,
including information retrieval, recommendation systems, and multimodal learning,
especially for systems that facilitate artistic creativity or discovery. Prior to starting graduate school, I was a Machine Learning Engineer at Amazon where I worked on NLP research and infrastructure for product classification. I recieved my bachelors degree in Computer Science from Georgia Tech in 2021, with a minor in Music Technology. My undergraduate research focused on representation learning methods for music performance assessment. Email / Linkedin / Github / Google Scholar |

|
|
|
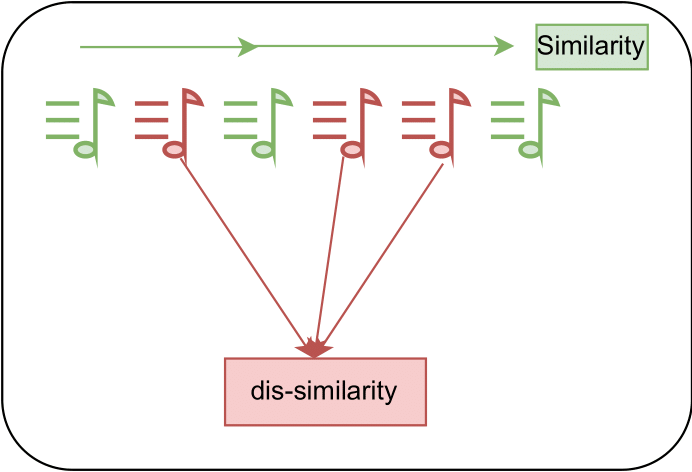 |
Pavan Seshadri, Shahrzad Shashaani, Peter Knees Proceedings of the 18th ACM Conference on Recommender Systems, Bari, Italy, RecSys 2024 arXiv / code We propose a contrastive learning task to model temporal negative feedback within the objective function of a sequential music recommender, and demonstrate consistent performance gains over feedback-agnostic systems. |
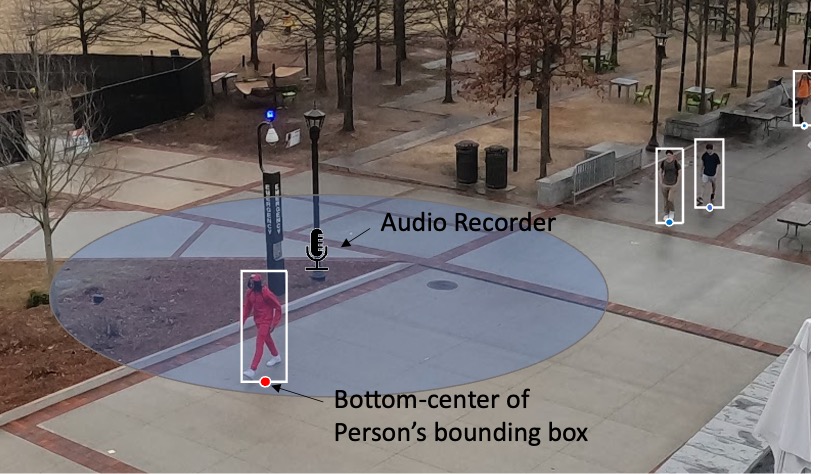 |
Pavan Seshadri, Chaeyeon Han, Bon-Woo Koo, Noah Posner, Subhrajit Guhathakurta, Alexander Lerch Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing,Seoul, South Korea, ICASSP 2024 arXiv / code / dataset We introduce the new audio analysis task of pedestrian detection and present a new large-scale dataset for this task. While the preliminary results prove the viability of using audio approaches for pedestrian detection, they also show that this challenging task cannot be easily solved with standard approaches. |
 |
Pavan Seshadri, Alexander Lerch Proceedings of the 22nd International Society for Music Information Retrieval, Online, ISMIR 2021 arXiv / code Contrastive loss based neural networks are able to exceed SoTA performance for music performance assessment (MPA) regression tasks by learning a better clustered latent space. |
|
|
 |
Shahrzad Shashaani, Pavan Seshadri, Peter Knees Proceedings of the 3rd Workshop on Music Recommender Systems, 19th ACM Conference on Recommender Systems, Prague, Czech Republic, MuRS @ RecSys 2025 arXiv / code (Coming soon) We analyze large-scale music recommendation datasets to observe key changes in listener patterns across different years of consumption and find stark differences in the performance of SoTA approaches for music recommendation isolated on specific time periods. |
 |
Pavan Seshadri, Peter Knees Proceedings of the 1st Workshop on Music Recommender Systems, 17th ACM Conference on Recommender Systems, Singapore, MuRS @ RecSys 2023 (Oral Presentation) arXiv / code We present a study using self-attentive architectures for next-track sequential music recommendation. We additionally propose a contrastive learning subtask to learn session-level track preference from implicit user signals, resulting in a 3-9% top-K hit rate performance increase relative to baseline negative feedback-agnostic approaches. |
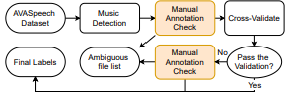 |
Yun-Ning Hung, Karn N. Watcharasupat, Chih-Wei Wu, Iroro Orife, Kelian Li, Pavan Seshadri, Junyoung Lee Late-Breaking Demos of the 22nd International Society for Music Information Retrieval, ISMIR 2021 LBD arXiv / code We propose a dataset, AVASpeech-SMAD, which provides frame-level music labels for the existing AVASpeech dataset, originally consisting of 45 hours of audio and speech activity labels. |
|
|
 |
Music.ai
Research Science Intern, Music Information Retrieval (2024) Mentors: Filip Korzeniowski & Richard Vogl |

|
Amazon
Software Development Engineer, Product Knowledge Classification (2021-2022) Software Development Engineer Intern, Browse Auto Classification (2020) |
|
|

|
Georgia Institute
of
Technology
Masters of Science, Music Technology (2022-2024) Bachelors of Science, Computer Science, Minor in Music Technology (2017-2021) Advisor: Prof. Alexander Lerch |
Template borrowed from Jon Barron